1 创建和等待多个线程
- 把thread对象放入到容器里管理,可理解为thread对象数组,这方便了我们一次创建大量的线程并对大量线程管理;
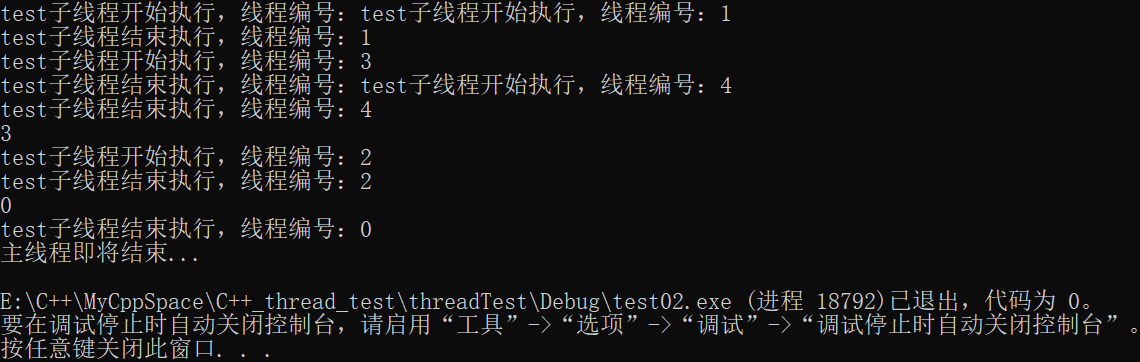
- 多个线程执行顺序是乱的,这与操作系统内部CPU调度算法有关;
- 推荐使用join,令主线程等待所有子线程运行结束,最后再结束主线程,这样程序更稳定;
// 多个线程公用一个线程入口函数
void test(int num) {
cout << "test子线程开始执行,线程编号:" << num << endl;
cout << "test子线程结束执行,线程编号:" << num << endl;
}
int main() {
vector<thread> mythreads;
int quantity = 5; // 创建5个子线程,入口函数统一为test
for (int i = 0; i < quantity; i++) {
mythreads.push_back(thread(test, i)); // 创建并开始执行线程,push_back的是thread的临时对象
}
for (vector<thread>::iterator it = mythreads.begin(); it != mythreads.end(); it++) {
it->join(); // 等待5个子线程均返回
}
cout << "主线程即将结束..." << endl;
return 0;
}
2 数据共享问题分析
2.1 只读的数据
只读的数据是安全稳定的,不需要特别的处理手段,直接读取即可,如下所示:
vector<int> g_v = { 1,2,3 }; // 创建全局变量作为【只读】共享数据
void test(int num) {
cout << "线程id为 " << std::this_thread::get_id() << " 的线程,打印g_v的值:" << g_v[0] << g_v[1] << g_v[2] << endl;
}
int main() {
vector<thread> mythreads;
int quantity = 5; // 创建5个子线程,入口函数统一为test
for (int i = 0; i < quantity; i++) {
mythreads.push_back(thread(test, i)); // 创建并开始执行线程,push_back的是thread的临时对象
}
for (vector<thread>::iterator it = mythreads.begin(); it != mythreads.end(); it++) {
it->join(); // 等待5个子线程均返回
}
return 0;
}

2.2 可读可写的数据
最简单的避免崩溃的处理是:【读】和【写】的操作是互斥进行的,即读的时候不能写、写的时候不能读。
3 共享数据的保护
假设要开发一个“网络游戏服务器”。创建两个线程,一个线程搜集玩家命令(用一个数字替代),并把命令数据写到一个队列中,另一个线程用于从队列中取出玩家的命令,进行解析后执行玩家需要的动作。这是一个不考虑容量的【生产者-消费者问题】,按理说生产者与消费者必须互斥地访问共享数据(缓冲区),但如果不进行互斥,如下述代码,则程序会崩溃:
class A {
public:
// 把收到的玩家命令入到链表中
void inMsg() {
for (int i = 0; i < 10000; i++) {
cout << "inMsg()执行,插入一个元素:" << i << endl;
msg.push_back(i); // 假设数字i就是收到的玩家命令
}
}
// 把数据从链表中取出
void outMsg() {
for (int i = 0; i < 10000; i++) {
if (!msg.empty()) {
int command = msg.front(); // 返回第一个元素
msg.pop_front(); // 移除第一个元素但不返回
}
else {
cout << "outMsg()执行,但目前消息队列为空" << i << endl;
}
}
cout << "end" << endl;
}
private:
list<int> msg; // 专门用于代表玩家发送过来的命令
};
int main() {
A a;
thread outObj(&A::outMsg, std::ref(a));
thread inObj(&A::inMsg, std::ref(a));
outObj.join();
inObj.join();
return 0;
}